OlmoEarth v1.1: A more efficient family of models
 A Blog post by Ai2 on Hugging Face
( 4
min )
A Blog post by Ai2 on Hugging Face
( 4
min )
A Blog post by Ai2 on Hugging Face
( 4
min )
A Blog post by Ai2 on Hugging Face
( 4
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 20
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 20
min )
 The syntax and semantics of mathematics
The post Introduction to Lean for Programmers appeared first on Towards Data Science.
( 20
min )
The syntax and semantics of mathematics
The post Introduction to Lean for Programmers appeared first on Towards Data Science.
( 20
min )
 Why production LLM systems need live web search to overcome knowledge cutoffs and stale training data
The post Grounding LLMs with Fresh Web Data to Reduce Hallucinations appeared first on Towards Data Science.
( 16
min )
Why production LLM systems need live web search to overcome knowledge cutoffs and stale training data
The post Grounding LLMs with Fresh Web Data to Reduce Hallucinations appeared first on Towards Data Science.
( 16
min )
 A scalable semantic localization layer for entity and relationship reconciliation
The post Proxy-Pointer RAG: Solving Entity and Relationship Sprawl in Large Knowledge Graphs appeared first on Towards Data Science.
( 23
min )
A scalable semantic localization layer for entity and relationship reconciliation
The post Proxy-Pointer RAG: Solving Entity and Relationship Sprawl in Large Knowledge Graphs appeared first on Towards Data Science.
( 23
min )
 The development of autonomous vehicles (AVs) is facing a data surge. Fleets with multi-sensor systems produce between 11 TB and
The post Sensor Data Triage Strategies for Scalable Autonomous Vehicle Training appeared first on iMerit.
( 9
min )
The development of autonomous vehicles (AVs) is facing a data surge. Fleets with multi-sensor systems produce between 11 TB and
The post Sensor Data Triage Strategies for Scalable Autonomous Vehicle Training appeared first on iMerit.
( 9
min )
 The production trade-offs that only appear once your model is live.
The post Six Choices Every AI Engineer Has to Make (and Nobody Teaches) appeared first on Towards Data Science.
( 16
min )
The production trade-offs that only appear once your model is live.
The post Six Choices Every AI Engineer Has to Make (and Nobody Teaches) appeared first on Towards Data Science.
( 16
min )
 Why MCP servers keep losing to CLIs once the agent gets a terminal
The post One Flexible Tool Beats a Hundred Dedicated Ones appeared first on Towards Data Science.
( 16
min )
Why MCP servers keep losing to CLIs once the agent gets a terminal
The post One Flexible Tool Beats a Hundred Dedicated Ones appeared first on Towards Data Science.
( 16
min )
 95% of enterprise AI pilots fail to launch. Why?
The post Why Your AI Demo Will Die in Production appeared first on Towards Data Science.
( 15
min )
95% of enterprise AI pilots fail to launch. Why?
The post Why Your AI Demo Will Die in Production appeared first on Towards Data Science.
( 15
min )
 A Blog post by NVIDIA on Hugging Face
( 10
min )
A Blog post by NVIDIA on Hugging Face
( 10
min )
 A Blog post by PaddlePaddle on Hugging Face
( 4
min )
A Blog post by PaddlePaddle on Hugging Face
( 4
min )
 A Blog post by IBM Research on Hugging Face
( 7
min )
A Blog post by IBM Research on Hugging Face
( 7
min )
 Billions of rows might be the exception, but for everything else, Pandas is still a highly reliable tool.
The post Pandas Isn’t Going Anywhere: Why It’s Still My Go-To for Data Wrangling appeared first on Towards Data Science.
( 14
min )
Billions of rows might be the exception, but for everything else, Pandas is still a highly reliable tool.
The post Pandas Isn’t Going Anywhere: Why It’s Still My Go-To for Data Wrangling appeared first on Towards Data Science.
( 14
min )
 Most LLM evaluation systems rely on vague scoring and human judgment disguised as metrics. I built a lightweight evaluation layer in pure Python that turns LLM outputs into reproducible decisions by separating attribution, specificity, and relevance—so hallucinations are caught before they reach production.
The post LLM Evals Are Based on Vibes — I Built the Missing Layer That Decides What Ships appeared first on Towards Data Science.
( 27
min )
Most LLM evaluation systems rely on vague scoring and human judgment disguised as metrics. I built a lightweight evaluation layer in pure Python that turns LLM outputs into reproducible decisions by separating attribution, specificity, and relevance—so hallucinations are caught before they reach production.
The post LLM Evals Are Based on Vibes — I Built the Missing Layer That Decides What Ships appeared first on Towards Data Science.
( 27
min )
 An eventful month with one flagship release after another
An eventful month with one flagship release after another
 The exact tools I'm learning, the projects I'm building, and the mistakes I'm already expecting to make
The post From Data Analyst to Data Engineer: My 12-Month Self-Study Roadmap appeared first on Towards Data Science.
( 16
min )
The exact tools I'm learning, the projects I'm building, and the mistakes I'm already expecting to make
The post From Data Analyst to Data Engineer: My 12-Month Self-Study Roadmap appeared first on Towards Data Science.
( 16
min )
 Exactly how does it differ from ReAct, CodeAct, Self-Loops, and Subagents?
The post Recursive Language Models: An All-in-One Deep Dive appeared first on Towards Data Science.
( 32
min )
Exactly how does it differ from ReAct, CodeAct, Self-Loops, and Subagents?
The post Recursive Language Models: An All-in-One Deep Dive appeared first on Towards Data Science.
( 32
min )
 Our recent paper, “LLMs Corrupt Your Documents When You Delegate”, has generated discussion about the reliability of AI systems in delegated workflows. We appreciate the interest in this work and want to clarify several important points about what the paper does—and does not—claim. The research aims to develop robust evaluation methods for long-horizon delegated and […]
The post Further Notes on Our Recent Research on AI Delegation and Long-Horizon Reliability appeared first on Microsoft Research.
( 12
min )
Our recent paper, “LLMs Corrupt Your Documents When You Delegate”, has generated discussion about the reliability of AI systems in delegated workflows. We appreciate the interest in this work and want to clarify several important points about what the paper does—and does not—claim. The research aims to develop robust evaluation methods for long-horizon delegated and […]
The post Further Notes on Our Recent Research on AI Delegation and Long-Horizon Reliability appeared first on Microsoft Research.
( 12
min )
 Learn how to make your Claude Code improve over time
The post How I Continually Improve My Claude Code appeared first on Towards Data Science.
( 17
min )
Learn how to make your Claude Code improve over time
The post How I Continually Improve My Claude Code appeared first on Towards Data Science.
( 17
min )
 From a Chinese prompt to a Korean response: an embedding-space investigation into how code vocabulary reshapes language
The post Why My Coding Assistant Started Replying in Korean When I Typed Chinese appeared first on Towards Data Science.
( 13
min )
From a Chinese prompt to a Korean response: an embedding-space investigation into how code vocabulary reshapes language
The post Why My Coding Assistant Started Replying in Korean When I Typed Chinese appeared first on Towards Data Science.
( 13
min )
 How to build a decision-grade scorecard for AI agents
The post Stop Evaluating LLMs with “Vibe Checks” appeared first on Towards Data Science.
( 15
min )
How to build a decision-grade scorecard for AI agents
The post Stop Evaluating LLMs with “Vibe Checks” appeared first on Towards Data Science.
( 15
min )
 Autonomous vehicles have come a long way. On controlled highways and structured urban environments, modern autonomous vehicle systems navigate familiar
The post Improving Autonomous Systems Through Edge Case Triage appeared first on iMerit.
( 9
min )
Autonomous vehicles have come a long way. On controlled highways and structured urban environments, modern autonomous vehicle systems navigate familiar
The post Improving Autonomous Systems Through Edge Case Triage appeared first on iMerit.
( 9
min )
 When enterprises evaluate AI data vendors, the discussion often centers on annotation accuracy, domain expertise, and delivery capacity. Yet many
The post Secure Data Operations & Governance in AI Vendor Evaluation appeared first on iMerit.
( 9
min )
When enterprises evaluate AI data vendors, the discussion often centers on annotation accuracy, domain expertise, and delivery capacity. Yet many
The post Secure Data Operations & Governance in AI Vendor Evaluation appeared first on iMerit.
( 9
min )
 A Blog post by IBM Granite on Hugging Face
( 13
min )
A Blog post by IBM Granite on Hugging Face
( 13
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 14
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 14
min )
 Enterprise AI systems are entering a phase where inference design matters as much as model capability itself.
The post The Next AI Bottleneck Isn’t the Model: It’s the Inference System appeared first on Towards Data Science.
( 13
min )
Enterprise AI systems are entering a phase where inference design matters as much as model capability itself.
The post The Next AI Bottleneck Isn’t the Model: It’s the Inference System appeared first on Towards Data Science.
( 13
min )
 A critical analysis of MRC's three counterintuitive design decisions, the networking mathematics that make them work, and what they mean for the rest of the AI infrastructure community.
The post The Counterintuitive Networking Decisions Behind OpenAI’s 131,000-GPU Training Fabric appeared first on Towards Data Science.
( 25
min )
A critical analysis of MRC's three counterintuitive design decisions, the networking mathematics that make them work, and what they mean for the rest of the AI infrastructure community.
The post The Counterintuitive Networking Decisions Behind OpenAI’s 131,000-GPU Training Fabric appeared first on Towards Data Science.
( 25
min )
 Improve the quality of Claude Code output.
The post How to Write Robust Code with Claude Code appeared first on Towards Data Science.
( 16
min )
Improve the quality of Claude Code output.
The post How to Write Robust Code with Claude Code appeared first on Towards Data Science.
( 16
min )
 A practical comparison between rule-based PDF extraction using pytesseract and an LLM-based approach with Ollama and LLaMA 3, based on a realistic B2B order scenario.
The post I Built the Same B2B Document Extractor Twice: Rules vs. LLM appeared first on Towards Data Science.
( 18
min )
A practical comparison between rule-based PDF extraction using pytesseract and an LLM-based approach with Ollama and LLaMA 3, based on a realistic B2B order scenario.
The post I Built the Same B2B Document Extractor Twice: Rules vs. LLM appeared first on Towards Data Science.
( 18
min )
 A beginner's tutorial on exploratory data analysis using Pandas, Matplolib, and Seaborn
The post Exploring Patterns of Survival from the Titanic Dataset appeared first on Towards Data Science.
( 18
min )
A beginner's tutorial on exploratory data analysis using Pandas, Matplolib, and Seaborn
The post Exploring Patterns of Survival from the Titanic Dataset appeared first on Towards Data Science.
( 18
min )
 A 12-metric evaluation framework for production AI agents — covering retrieval, generation, agent behavior, and production health. Drawn from 100+ enterprise deployments.
The post Building an Evaluation Harness for Production AI Agents: A 12-Metric Framework From 100+ Deployments appeared first on Towards Data Science.
( 23
min )
A 12-metric evaluation framework for production AI agents — covering retrieval, generation, agent behavior, and production health. Drawn from 100+ enterprise deployments.
The post Building an Evaluation Harness for Production AI Agents: A 12-Metric Framework From 100+ Deployments appeared first on Towards Data Science.
( 23
min )
 As healthcare AI adoption accelerates, the ability to de-identify sensitive patient data while preserving clinical value has become mission-critical. From
The post Top Medical Data De-Identification Companies in 2026 appeared first on iMerit.
( 7
min )
As healthcare AI adoption accelerates, the ability to de-identify sensitive patient data while preserving clinical value has become mission-critical. From
The post Top Medical Data De-Identification Companies in 2026 appeared first on iMerit.
( 7
min )
 Healthcare is experiencing a data-driven revolution. From AI models that read radiology scans to predictive algorithms guiding clinical workflows, the
The post De-Identifying Medical Data: Challenges, Innovations, and What’s Next appeared first on iMerit.
( 7
min )
Healthcare is experiencing a data-driven revolution. From AI models that read radiology scans to predictive algorithms guiding clinical workflows, the
The post De-Identifying Medical Data: Challenges, Innovations, and What’s Next appeared first on iMerit.
( 7
min )
 mimalloc is an open-source, modern, scalable memory allocator that is a drop-in replacement for malloc and free. It is relatively small (~12K lines), with clear internal data structures, and is easy to build and integrate into other projects. It provides bounded worst-case allocation times (up to OS primitives), bounded space overhead, low internal fragmentation, and minimal contention by relying almost exclusively on atomic operations.
The post mimalloc: A new, high-performance, scalable memory allocator for the modern era appeared first on Microsoft Research.
( 17
min )
mimalloc is an open-source, modern, scalable memory allocator that is a drop-in replacement for malloc and free. It is relatively small (~12K lines), with clear internal data structures, and is easy to build and integrate into other projects. It provides bounded worst-case allocation times (up to OS primitives), bounded space overhead, low internal fragmentation, and minimal contention by relying almost exclusively on atomic operations.
The post mimalloc: A new, high-performance, scalable memory allocator for the modern era appeared first on Microsoft Research.
( 17
min )
 A 4.5-hour journey from idea to working fitness app with LLM agents
The post From Vibe Coding to Spec-Driven Development appeared first on Towards Data Science.
( 20
min )
A 4.5-hour journey from idea to working fitness app with LLM agents
The post From Vibe Coding to Spec-Driven Development appeared first on Towards Data Science.
( 20
min )
 When semantic search isn't enough for the RAG
The post Hybrid Search and Re-Ranking in Production RAG appeared first on Towards Data Science.
( 21
min )
When semantic search isn't enough for the RAG
The post Hybrid Search and Re-Ranking in Production RAG appeared first on Towards Data Science.
( 21
min )
 Hierarchical understanding and comparison of contracts, research papers, and more
The post Proxy-Pointer RAG — Structure-Aware Document Comparison at Enterprise Scale appeared first on Towards Data Science.
( 16
min )
Hierarchical understanding and comparison of contracts, research papers, and more
The post Proxy-Pointer Framework for Structure-Aware Enterprise Document Intelligence appeared first on Towards Data Science.
( 16
min )
Hierarchical understanding and comparison of contracts, research papers, and more
The post Proxy-Pointer RAG — Structure-Aware Document Comparison at Enterprise Scale appeared first on Towards Data Science.
( 16
min )
Hierarchical understanding and comparison of contracts, research papers, and more
The post Proxy-Pointer Framework for Structure-Aware Enterprise Document Intelligence appeared first on Towards Data Science.
( 16
min )
 Compiling and running C code with Emscripten and GitHub Codespaces — no local installation required.
The post Your First WebAssembly Program and Web App (Written, Tested, and Deployed Entirely in the Web Browser) appeared first on Towards Data Science.
( 20
min )
Compiling and running C code with Emscripten and GitHub Codespaces — no local installation required.
The post Your First WebAssembly Program and Web App (Written, Tested, and Deployed Entirely in the Web Browser) appeared first on Towards Data Science.
( 20
min )
 Further reflections on China's high-participation, open-first AI ecosystem.
Further reflections on China's high-participation, open-first AI ecosystem.
 MatterSim is expanding what AI can do for materials science—from faster large-scale simulations to MatterSim-MT, a new multi-task model for simulating properties beyond potential energy surfaces alone.
The post Advancing AI for materials with MatterSim: experimental synthesis, faster simulation, and multi-task models appeared first on Microsoft Research.
( 17
min )
MatterSim is expanding what AI can do for materials science—from faster large-scale simulations to MatterSim-MT, a new multi-task model for simulating properties beyond potential energy surfaces alone.
The post Advancing AI for materials with MatterSim: experimental synthesis, faster simulation, and multi-task models appeared first on Microsoft Research.
( 17
min )
 Every product experimentation team doing causal inference on LLM-based features eventually hits the same wall: when the provider ships a new model version, there's no holdout. Your infrastructure team
( 16
min )
Every product experimentation team doing causal inference on LLM-based features eventually hits the same wall: when the provider ships a new model version, there's no holdout. Your infrastructure team
( 16
min )
 A Blog post by Amazon on Hugging Face
( 15
min )
A Blog post by Amazon on Hugging Face
( 15
min )
 How to build sentiment-aware word representations from IMDb reviews using semantic learning, star ratings, and linear SVM classification
The post Learning Word Vectors for Sentiment Analysis: A Python Reproduction appeared first on Towards Data Science.
( 19
min )
How to build sentiment-aware word representations from IMDb reviews using semantic learning, star ratings, and linear SVM classification
The post Learning Word Vectors for Sentiment Analysis: A Python Reproduction appeared first on Towards Data Science.
( 19
min )
 Perform efficient data retrieval of personal knowledge
The post How to Build a Claude Code-Powered Knowledge Base appeared first on Towards Data Science.
( 16
min )
Perform efficient data retrieval of personal knowledge
The post How to Build a Claude Code-Powered Knowledge Base appeared first on Towards Data Science.
( 16
min )
 How ML can change for rare events
The post Using Transformers to Forecast Incredibly Rare Solar Flares appeared first on Towards Data Science.
( 16
min )
How ML can change for rare events
The post Using Transformers to Forecast Incredibly Rare Solar Flares appeared first on Towards Data Science.
( 16
min )
 Using SocialReasoning Bench, we observed a stable pattern across models—agents execute competently, but fail to consistently improve the user’s position, even with explicit instructions to optimize for user interest.
The post SocialReasoning-Bench: Measuring whether AI agents act in users’ best interests appeared first on Microsoft Research.
( 20
min )
Using SocialReasoning Bench, we observed a stable pattern across models—agents execute competently, but fail to consistently improve the user’s position, even with explicit instructions to optimize for user interest.
The post SocialReasoning-Bench: Measuring whether AI agents act in users’ best interests appeared first on Microsoft Research.
( 20
min )
 A Blog post by Lablab.ai AMD Developer Hackathon on Hugging Face
( 5
min )
A Blog post by Lablab.ai AMD Developer Hackathon on Hugging Face
( 5
min )
 A practitioner's argument that meeting summarizers fail in the same way regressions fail when you skip the part where you ask what the data can support.
The post LLM Summarizers Skip the Identification Step appeared first on Towards Data Science.
( 20
min )
A practitioner's argument that meeting summarizers fail in the same way regressions fail when you skip the part where you ask what the data can support.
The post LLM Summarizers Skip the Identification Step appeared first on Towards Data Science.
( 20
min )
 Learn YOLOE for real-time open-vocabulary object detection and instance segmentation in Python with Ultralytics — text, visual, and prompt-free modes.
How to Master YOLOE: Real-Time Open-Vocabulary Detection Made Easy first appeared on LearnOpenCV.
( 28
min )
Learn YOLOE for real-time open-vocabulary object detection and instance segmentation in Python with Ultralytics — text, visual, and prompt-free modes.
How to Master YOLOE: Real-Time Open-Vocabulary Detection Made Easy first appeared on LearnOpenCV.
( 28
min )
 Microsoft Research is excited to release an open dataset of approximate transmission topology of the U.S. power grid derived from publicly available data. The ability to study transmission-level power grid behavior is essential for modern power systems research. Analyses of congestion, transmission expansion, demand growth, and system resilience all depend on network models with realistic […]
The post Building realistic electric transmission grid dataset at scale: a pipeline from open dataset appeared first on Microsoft Research.
( 17
min )
Microsoft Research is excited to release an open dataset of approximate transmission topology of the U.S. power grid derived from publicly available data. The ability to study transmission-level power grid behavior is essential for modern power systems research. Analyses of congestion, transmission expansion, demand growth, and system resilience all depend on network models with realistic […]
The post Building realistic electric transmission grid dataset at scale: a pipeline from open dataset appeared first on Microsoft Research.
( 17
min )
 Standard prompt attacks are merely the beginning. A structured framework to map and mitigate the backend attack vectors of agentic workflows.
The post The AI Agent Security Surface: What Gets Exposed When You Add Tools and Memory appeared first on Towards Data Science.
( 17
min )
Standard prompt attacks are merely the beginning. A structured framework to map and mitigate the backend attack vectors of agentic workflows.
The post The AI Agent Security Surface: What Gets Exposed When You Add Tools and Memory appeared first on Towards Data Science.
( 17
min )
 A practitioner's guide to causal attribution when two churn drivers arrive at once.
The post When Customers Churn at Renewal: Was It the Price or the Project? appeared first on Towards Data Science.
( 20
min )
A practitioner's guide to causal attribution when two churn drivers arrive at once.
The post When Customers Churn at Renewal: Was It the Price or the Project? appeared first on Towards Data Science.
( 20
min )
 A Blog post by Lablab.ai AMD Developer Hackathon on Hugging Face
( 7
min )
A Blog post by Lablab.ai AMD Developer Hackathon on Hugging Face
( 7
min )
 A Blog post by Ai2 on Hugging Face
( 7
min )
A Blog post by Ai2 on Hugging Face
( 7
min )
 Causal inference for LLM-based features starts with one question editors ask before they ship anything: Did the change actually move the metric, or did the metric just move? Let's say that your team b
( 16
min )
Causal inference for LLM-based features starts with one question editors ask before they ship anything: Did the change actually move the metric, or did the metric just move? Let's say that your team b
( 16
min )
 Because there's only one reality to model!
The post How Major Reasoning Models Converge to the Same “Brain” as They Model Reality Increasingly Better appeared first on Towards Data Science.
( 15
min )
Because there's only one reality to model!
The post How Major Reasoning Models Converge to the Same “Brain” as They Model Reality Increasingly Better appeared first on Towards Data Science.
( 15
min )
 From 61 seconds to 0.20 seconds — and the mental model shift I didn't expect
The post I Rewrote a Real Data Workflow in Polars. Pandas Didn’t Stand a Chance. appeared first on Towards Data Science.
( 20
min )
From 61 seconds to 0.20 seconds — and the mental model shift I didn't expect
The post I Rewrote a Real Data Workflow in Polars. Pandas Didn’t Stand a Chance. appeared first on Towards Data Science.
( 20
min )
 Lessons from my trip to talk to most of the leading AI labs in China.
Lessons from my trip to talk to most of the leading AI labs in China.
 A Blog post by ServiceNow-AI on Hugging Face
( 6
min )
A Blog post by ServiceNow-AI on Hugging Face
( 6
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 7
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 7
min )
 We use AI tools all the time, whether it’s asking questions, generating images, or getting help with everyday tasks. But most of these tools didn’t appear out of nowhere. They were developed based on
( 10
min )
We use AI tools all the time, whether it’s asking questions, generating images, or getting help with everyday tasks. But most of these tools didn’t appear out of nowhere. They were developed based on
( 10
min )
We use AI tools all the time, whether it’s asking questions, generating images, or getting help with everyday tasks. But most of these tools didn’t appear out of nowhere. They were developed based on
( 10
min )
We use AI tools all the time, whether it’s asking questions, generating images, or getting help with everyday tasks. But most of these tools didn’t appear out of nowhere. They were developed based on
( 10
min )
 A scenario analysis case study on calibrated uncertainty, historical error, and why some models are most useful when they refuse to forecast.
The post When the Uncertainty Is Bigger Than the Shock: Scenario Modelling for English Local Elections appeared first on Towards Data Science.
( 19
min )
A scenario analysis case study on calibrated uncertainty, historical error, and why some models are most useful when they refuse to forecast.
The post When the Uncertainty Is Bigger Than the Shock: Scenario Modelling for English Local Elections appeared first on Towards Data Science.
( 19
min )
 Stop shifting elements in lists! Discover why collections.deque is the secret to high-performance sliding windows, thread-safe queues, and efficient data streams in your next Python project.
The post Beyond Lists: Using Python Deque for Real-Time Sliding Windows appeared first on Towards Data Science.
( 13
min )
Stop shifting elements in lists! Discover why collections.deque is the secret to high-performance sliding windows, thread-safe queues, and efficient data streams in your next Python project.
The post Beyond Lists: Using Python Deque for Real-Time Sliding Windows appeared first on Towards Data Science.
( 13
min )
 Exploring the inner workings of a decoder-only Transformer foundation model
The post Timer-XL: A Long-Context Foundation Model for Time-Series Forecasting appeared first on Towards Data Science.
( 19
min )
Exploring the inner workings of a decoder-only Transformer foundation model
The post Timer-XL: A Long-Context Foundation Model for Time-Series Forecasting appeared first on Towards Data Science.
( 19
min )
 A physicist's approach to building production-grade agents
The post Why I Don’t Trust LLMs to Decide When the Weather Changed appeared first on Towards Data Science.
( 15
min )
A physicist's approach to building production-grade agents
The post Why I Don’t Trust LLMs to Decide When the Weather Changed appeared first on Towards Data Science.
( 15
min )
 What you see is rarely what you get with flashy dashboards and data storytelling
The post Deconstruct Any Metric with a Few Simple ‘What’ Questions appeared first on Towards Data Science.
( 14
min )
What you see is rarely what you get with flashy dashboards and data storytelling
The post Deconstruct Any Metric with a Few Simple ‘What’ Questions appeared first on Towards Data Science.
( 14
min )
 Multimodal annotation is the foundation of reliable robotics AI. When training data spans camera, LiDAR, radar, and depth inputs in
The post Precision at Scale: Building Robust Robotics AI with Multimodal Annotation appeared first on iMerit.
( 7
min )
Multimodal annotation is the foundation of reliable robotics AI. When training data spans camera, LiDAR, radar, and depth inputs in
The post Precision at Scale: Building Robust Robotics AI with Multimodal Annotation appeared first on iMerit.
( 7
min )
 Multimodal annotation is the foundation of reliable robotics AI. When training data spans camera, LiDAR, radar, and depth inputs in
The post Precision at Scale: Building Robust Robotics AI with Multimodal Annotation appeared first on iMerit.
( 7
min )
Multimodal annotation is the foundation of reliable robotics AI. When training data spans camera, LiDAR, radar, and depth inputs in
The post Precision at Scale: Building Robust Robotics AI with Multimodal Annotation appeared first on iMerit.
( 7
min )
 In our daily life, we use the word "average" all the time: average salary, average marks, average age, and so on. Let's take the case of a retail shop. If we're looking at the average order value to u
( 9
min )
In our daily life, we use the word "average" all the time: average salary, average marks, average age, and so on. Let's take the case of a retail shop. If we're looking at the average order value to u
( 9
min )
 Part 1: The basics — discretization of time, censoring and the life table
The post Discrete Time-To-Event Modeling – Predicting When Something Will Happen appeared first on Towards Data Science.
( 17
min )
Part 1: The basics — discretization of time, censoring and the life table
The post Discrete Time-To-Event Modeling – Predicting When Something Will Happen appeared first on Towards Data Science.
( 17
min )
 Improve Claude Code performance by having it validate its own work
The post How to Make Claude Code Validate its own Work appeared first on Towards Data Science.
( 15
min )
Improve Claude Code performance by having it validate its own work
The post How to Make Claude Code Validate its own Work appeared first on Towards Data Science.
( 15
min )
 Your RAG system isn’t failing at retrieval — it’s failing at reasoning. This article shows how I built a lightweight self-healing layer that detects and corrects hallucinations before they reach users.
The post RAG Hallucinates — I Built a Self-Healing Layer That Fixes It in Real Time appeared first on Towards Data Science.
( 28
min )
Your RAG system isn’t failing at retrieval — it’s failing at reasoning. This article shows how I built a lightweight self-healing layer that detects and corrects hallucinations before they reach users.
The post RAG Hallucinates — I Built a Self-Healing Layer That Fixes It in Real Time appeared first on Towards Data Science.
( 28
min )
 Part 2. Building scale-invariant agents that seamlessly change contexts
The post Surviving High Uncertainty in Logistics with MARL appeared first on Towards Data Science.
( 17
min )
Part 2. Building scale-invariant agents that seamlessly change contexts
The post Surviving High Uncertainty in Logistics with MARL appeared first on Towards Data Science.
( 17
min )
 Microsoft researchers share advances in building and operating large-scale distributed systems, spanning datacenters, networking, and the growing intersection with AI during NSDI ’26.
The post Microsoft at NSDI 2026: Advances in large-scale networked systems appeared first on Microsoft Research.
( 14
min )
Microsoft researchers share advances in building and operating large-scale distributed systems, spanning datacenters, networking, and the growing intersection with AI during NSDI ’26.
The post Microsoft at NSDI 2026: Advances in large-scale networked systems appeared first on Microsoft Research.
( 14
min )
 A practical guide to understanding AI agent design, ReAct workflows, and when to scale from a single agent to a multi-agent system.
The post Single Agent vs Multi-Agent: When to Build a Multi-Agent System appeared first on Towards Data Science.
( 19
min )
A practical guide to understanding AI agent design, ReAct workflows, and when to scale from a single agent to a multi-agent system.
The post Single Agent vs Multi-Agent: When to Build a Multi-Agent System appeared first on Towards Data Science.
( 19
min )
 Building a knowledge base for AI models isn’t a one-time task but an iterative process of refinement.
The post How to Build an Efficient Knowledge Base for AI Models appeared first on Towards Data Science.
( 21
min )
Building a knowledge base for AI models isn’t a one-time task but an iterative process of refinement.
The post How to Build an Efficient Knowledge Base for AI Models appeared first on Towards Data Science.
( 21
min )
 Solving multiplayer games with function approximation
The post Playing Connect Four with Deep Q-Learning appeared first on Towards Data Science.
( 16
min )
Solving multiplayer games with function approximation
The post Playing Connect Four with Deep Q-Learning appeared first on Towards Data Science.
( 16
min )
 AI tools speed up IoT development — but closer to the hardware, the same code that looks correct can silently break thousands of devices at once.
The post How AI Tools Generate Technical Debt in IoT Systems — and What to Do About It appeared first on Towards Data Science.
( 15
min )
AI tools speed up IoT development — but closer to the hardware, the same code that looks correct can silently break thousands of devices at once.
The post How AI Tools Generate Technical Debt in IoT Systems — and What to Do About It appeared first on Towards Data Science.
( 15
min )
 ‘Distillation attacks’ is a horrible term for what is happening right now.
‘Distillation attacks’ is a horrible term for what is happening right now.
 A review of the Cross-Stage Partial Network paper — and a from-scratch PyTorch implementation
The post CSPNet Paper Walkthrough: Just Better, No Tradeoffs appeared first on Towards Data Science.
( 28
min )
A review of the Cross-Stage Partial Network paper — and a from-scratch PyTorch implementation
The post CSPNet Paper Walkthrough: Just Better, No Tradeoffs appeared first on Towards Data Science.
( 28
min )
 Why reasoning models dramatically increase token usage, latency, and infrastructure costs in production systems
The post Inference Scaling (Test-Time Compute): Why Reasoning Models Raise Your Compute Bill appeared first on Towards Data Science.
( 17
min )
Why reasoning models dramatically increase token usage, latency, and infrastructure costs in production systems
The post Inference Scaling (Test-Time Compute): Why Reasoning Models Raise Your Compute Bill appeared first on Towards Data Science.
( 17
min )
 A practitioner's decision framework for Ridge, Lasso, and ElasticNet based on three quantities you can compute before fitting a model
The post Which Regularizer Should You Actually Use? Lessons from 134,400 Simulations appeared first on Towards Data Science.
( 19
min )
A practitioner's decision framework for Ridge, Lasso, and ElasticNet based on three quantities you can compute before fitting a model
The post Which Regularizer Should You Actually Use? Lessons from 134,400 Simulations appeared first on Towards Data Science.
( 19
min )
 One scale parameter determines accuracy in rotation-based vector quantization.
The post How a 2021 Quantization Algorithm Quietly Outperforms Its 2026 Successor appeared first on Towards Data Science.
( 15
min )
One scale parameter determines accuracy in rotation-based vector quantization.
The post How a 2021 Quantization Algorithm Quietly Outperforms Its 2026 Successor appeared first on Towards Data Science.
( 15
min )
 A data quality case study from English local elections on categorical normalisation, metric validation, and why raw labels should never define analytical groups.
The post Churn Without Fragmentation: How a Party-Label Bug Reversed My Headline Finding appeared first on Towards Data Science.
( 18
min )
A data quality case study from English local elections on categorical normalisation, metric validation, and why raw labels should never define analytical groups.
The post Churn Without Fragmentation: How a Party-Label Bug Reversed My Headline Finding appeared first on Towards Data Science.
( 18
min )
 The first database built for AI Agents
The post Ghost: A Database for Our Times? appeared first on Towards Data Science.
( 19
min )
The first database built for AI Agents
The post Ghost: A Database for Our Times? appeared first on Towards Data Science.
( 19
min )
 Or why what appears powerful can be methodologically fragile
The post Why Powerful Machine Learning Is Deceptively Easy appeared first on Towards Data Science.
( 21
min )
Or why what appears powerful can be methodologically fragile
The post Why Powerful Machine Learning Is Deceptively Easy appeared first on Towards Data Science.
( 21
min )
 Every product experimentation team running causal inference on LLM-based features eventually hits the same wall: when users click "Try our AI assistant," the volunteers aren't a random sample. Your pr
( 16
min )
Every product experimentation team running causal inference on LLM-based features eventually hits the same wall: when users click "Try our AI assistant," the volunteers aren't a random sample. Your pr
( 16
min )
 Safe agents don’t guarantee a safe ecosystem of interconnected agents. Microsoft Research examines what breaks when AI agents interact and why network-level risks require new approaches.
The post Red-teaming a network of agents: Understanding what breaks when AI agents interact at scale appeared first on Microsoft Research.
( 19
min )
Safe agents don’t guarantee a safe ecosystem of interconnected agents. Microsoft Research examines what breaks when AI agents interact and why network-level risks require new approaches.
The post Red-teaming a network of agents: Understanding what breaks when AI agents interact at scale appeared first on Microsoft Research.
( 19
min )
 How to make decisions when your spreadsheet is lying about the future
The post A Gentle Introduction to Stochastic Programming appeared first on Towards Data Science.
( 19
min )
How to make decisions when your spreadsheet is lying about the future
The post A Gentle Introduction to Stochastic Programming appeared first on Towards Data Science.
( 19
min )
 Structure is all you need
The post Proxy-Pointer RAG: Multimodal Answers Without Multimodal Embeddings appeared first on Towards Data Science.
( 20
min )
Structure is all you need
The post Proxy-Pointer RAG: Multimodal Answers Without Multimodal Embeddings appeared first on Towards Data Science.
( 20
min )
 How can you validate that your variables tell a consistent risk?
The post How to Study the Monotonicity and Stability of Variables in a Scoring Model using Python appeared first on Towards Data Science.
( 16
min )
How can you validate that your variables tell a consistent risk?
The post How to Study the Monotonicity and Stability of Variables in a Scoring Model using Python appeared first on Towards Data Science.
( 16
min )
 Frameworks accelerated the first wave of LLM apps, but production demands a different architecture.
The post Why AI Engineers Are Moving Beyond LangChain to Native Agent Architectures appeared first on Towards Data Science.
( 15
min )
Frameworks accelerated the first wave of LLM apps, but production demands a different architecture.
The post Why AI Engineers Are Moving Beyond LangChain to Native Agent Architectures appeared first on Towards Data Science.
( 15
min )
 In today's digital world, spam is no longer just an annoyance - it's a growing security threat. To combat this, developers often turn to machine learning to build intelligent filters that can distingu
( 11
min )
In today's digital world, spam is no longer just an annoyance - it's a growing security threat. To combat this, developers often turn to machine learning to build intelligent filters that can distingu
( 11
min )
 A Blog post by EvalEval Coalition on Hugging Face
( 13
min )
A Blog post by EvalEval Coalition on Hugging Face
( 13
min )
 A Blog post by IBM Granite on Hugging Face
( 11
min )
A Blog post by IBM Granite on Hugging Face
( 11
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 4
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 4
min )
 How we replaced Python pipelines with dlt, dbt, and Trino — and cut delivery time from weeks to one day.
The post 4 YAML Files Instead of PySpark: How We Let Analysts Build Data Pipelines Without Engineers appeared first on Towards Data Science.
( 17
min )
How we replaced Python pipelines with dlt, dbt, and Trino — and cut delivery time from weeks to one day.
The post 4 YAML Files Instead of PySpark: How We Let Analysts Build Data Pipelines Without Engineers appeared first on Towards Data Science.
( 17
min )
 The best machine learning model is not one model
The post Ensembles of Ensembles of Ensembles: A Guide to Stacking appeared first on Towards Data Science.
( 16
min )
The best machine learning model is not one model
The post Ensembles of Ensembles of Ensembles: A Guide to Stacking appeared first on Towards Data Science.
( 16
min )
 A deep dive into how Apache Flink works, why it exists, and learning it while building a real-time recommendation engine
The post System Design Series: Apache Flink from 10,000 Feet, and Building a Flink-powered Recommendation Engine appeared first on Towards Data Science.
( 21
min )
A deep dive into how Apache Flink works, why it exists, and learning it while building a real-time recommendation engine
The post System Design Series: Apache Flink from 10,000 Feet, and Building a Flink-powered Recommendation Engine appeared first on Towards Data Science.
( 21
min )
 LiDAR sensor fusion annotation combines labeled 3D point cloud data with synchronized camera and radar inputs to give autonomous vehicle
The post LiDAR Sensor Fusion: Annotating 3D Point Clouds for Safer Autonomous Vehicles appeared first on iMerit.
( 8
min )
LiDAR sensor fusion annotation combines labeled 3D point cloud data with synchronized camera and radar inputs to give autonomous vehicle
The post LiDAR Sensor Fusion: Annotating 3D Point Clouds for Safer Autonomous Vehicles appeared first on iMerit.
( 8
min )
 LiDAR sensor fusion annotation combines labeled 3D point cloud data with synchronized camera and radar inputs to give autonomous vehicle
The post LiDAR Sensor Fusion: Annotating 3D Point Clouds for Safer Autonomous Vehicles appeared first on iMerit.
( 8
min )
LiDAR sensor fusion annotation combines labeled 3D point cloud data with synchronized camera and radar inputs to give autonomous vehicle
The post LiDAR Sensor Fusion: Annotating 3D Point Clouds for Safer Autonomous Vehicles appeared first on iMerit.
( 8
min )
 What does correlation tells us?
The post Correlation Doesn’t Mean Causation! But What Does It Mean? appeared first on Towards Data Science.
( 14
min )
What does correlation tells us?
The post Correlation Doesn’t Mean Causation! But What Does It Mean? appeared first on Towards Data Science.
( 14
min )
 Blast-radius control tells you how much to break. Intent tells you what breaking it will teach. Only one of these has mature tooling.
The post The Next Frontier of AI in Production Is Chaos Engineering appeared first on Towards Data Science.
( 22
min )
Blast-radius control tells you how much to break. Intent tells you what breaking it will teach. Only one of these has mature tooling.
The post The Next Frontier of AI in Production Is Chaos Engineering appeared first on Towards Data Science.
( 22
min )
 NaNs don’t crash your training — they quietly destroy it.
The post PyTorch NaNs Are Silent Killers — So I Built a 3ms Hook to Catch Them at the Exact Layer appeared first on Towards Data Science.
( 18
min )
NaNs don’t crash your training — they quietly destroy it.
The post PyTorch NaNs Are Silent Killers — So I Built a 3ms Hook to Catch Them at the Exact Layer appeared first on Towards Data Science.
( 18
min )
 A Blog post by NVIDIA on Hugging Face
( 13
min )
A Blog post by NVIDIA on Hugging Face
( 13
min )
 A Blog post by NVIDIA on Hugging Face
( 4
min )
A Blog post by NVIDIA on Hugging Face
( 4
min )
 Sabrine Bendimerad on why flexibility is a crucial data science skill, the risks of outsourcing human thinking to AI agents, and the changing terrain of career paths today.
The post A Career in Data Is Not Always a Straight Line, and That’s Okay appeared first on Towards Data Science.
( 16
min )
Sabrine Bendimerad on why flexibility is a crucial data science skill, the risks of outsourcing human thinking to AI agents, and the changing terrain of career paths today.
The post A Career in Data Is Not Always a Straight Line, and That’s Okay appeared first on Towards Data Science.
( 16
min )
 A simulation of how a single forecast change moves through five planning teams, and why most retailers lose money in the gap between Sales and Stores.
The post How Spreadsheets Quietly Cost Supply Chains Millions appeared first on Towards Data Science.
( 19
min )
A simulation of how a single forecast change moves through five planning teams, and why most retailers lose money in the gap between Sales and Stores.
The post How Spreadsheets Quietly Cost Supply Chains Millions appeared first on Towards Data Science.
( 19
min )
 With the advent of UDFs and their combination with calculation groups, I see a lot of discussion about not creating explicit measures but instead offering calculation groups to report creators.
The post Comparing Explicit Measures to Calculation Groups in Tabular Models appeared first on Towards Data Science.
( 14
min )
With the advent of UDFs and their combination with calculation groups, I see a lot of discussion about not creating explicit measures but instead offering calculation groups to report creators.
The post Comparing Explicit Measures to Calculation Groups in Tabular Models appeared first on Towards Data Science.
( 14
min )
 iMerit asserts that agronomy expertise is the “secret ingredient” for weeding robot accuracy, bridging the gap between lab models and
The post Why Agronomy Expertise is the Secret Ingredient for Weeding Robot Accuracy appeared first on iMerit.
( 9
min )
iMerit asserts that agronomy expertise is the “secret ingredient” for weeding robot accuracy, bridging the gap between lab models and
The post Why Agronomy Expertise is the Secret Ingredient for Weeding Robot Accuracy appeared first on iMerit.
( 9
min )
 iMerit asserts that agronomy expertise is the “secret ingredient” for weeding robot accuracy, bridging the gap between lab models and
The post Why Agronomy Expertise is the Secret Ingredient for Weeding Robot Accuracy appeared first on iMerit.
( 9
min )
iMerit asserts that agronomy expertise is the “secret ingredient” for weeding robot accuracy, bridging the gap between lab models and
The post Why Agronomy Expertise is the Secret Ingredient for Weeding Robot Accuracy appeared first on iMerit.
( 9
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 6
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 6
min )
 Why learn 8 scripts when you can learn 256 bytes?
The post Bytes Speak All Languages: Cross-Script Name Retrieval via Contrastive Learning appeared first on Towards Data Science.
( 18
min )
Why learn 8 scripts when you can learn 256 bytes?
The post Bytes Speak All Languages: Cross-Script Name Retrieval via Contrastive Learning appeared first on Towards Data Science.
( 18
min )
 Most slow Pandas code "works", until it doesn't. Learn how to spot hidden bottlenecks, avoid costly row-wise operations, and know when Pandas is no longer enough.
The post I Reduced My Pandas Runtime by 95% — Here’s What I Was Doing Wrong appeared first on Towards Data Science.
( 23
min )
Most slow Pandas code "works", until it doesn't. Learn how to spot hidden bottlenecks, avoid costly row-wise operations, and know when Pandas is no longer enough.
The post I Reduced My Pandas Runtime by 95% — Here’s What I Was Doing Wrong appeared first on Towards Data Science.
( 23
min )
 How does decision-gravity dictate this gap?
The post Causal Inference Is Different in Business appeared first on Towards Data Science.
( 18
min )
How does decision-gravity dictate this gap?
The post Causal Inference Is Different in Business appeared first on Towards Data Science.
( 18
min )
 We have the document clusters, and it’s time to unlock their true potential! Let’s explore how to extract meaningful information from the actionable clusters.
The post The Essential Guide to Effectively Summarizing Massive Documents, Part 2 appeared first on Towards Data Science.
( 22
min )
We have the document clusters, and it’s time to unlock their true potential! Let’s explore how to extract meaningful information from the actionable clusters.
The post The Essential Guide to Effectively Summarizing Massive Documents, Part 2 appeared first on Towards Data Science.
( 22
min )
 Learn about function approximation and the different choices for approximation functions
The post Introduction to Approximate Solution Methods for Reinforcement Learning appeared first on Towards Data Science.
( 16
min )
Learn about function approximation and the different choices for approximation functions
The post Introduction to Approximate Solution Methods for Reinforcement Learning appeared first on Towards Data Science.
( 16
min )
 Learn how to get the most out of Claude Code
The post How to Improve Claude Code Performance with Automated Testing appeared first on Towards Data Science.
( 17
min )
Learn how to get the most out of Claude Code
The post How to Improve Claude Code Performance with Automated Testing appeared first on Towards Data Science.
( 17
min )
 More variables don't make a better scoring model. Stable variables do. Here's how to find them.
The post How to Select Variables Robustly in a Scoring Model appeared first on Towards Data Science.
( 14
min )
More variables don't make a better scoring model. Stable variables do. Here's how to find them.
The post How to Select Variables Robustly in a Scoring Model appeared first on Towards Data Science.
( 14
min )
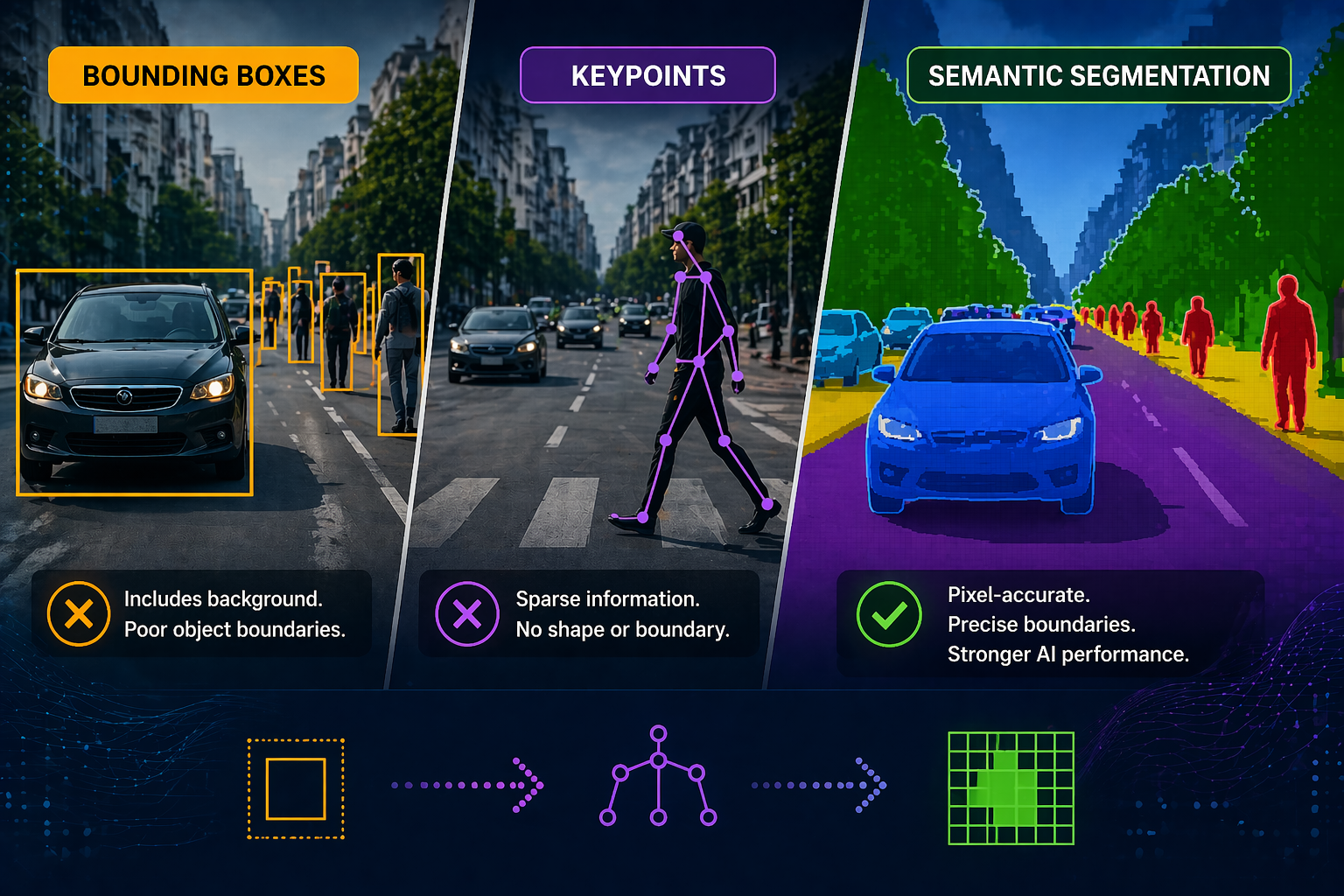 Precision in AI is critical across domains like healthcare, autonomous driving, agriculture, and industrial inspection, where inaccuracies are unacceptable. Coarse
The post Why Semantic Segmentation Outperforms Bounding Boxes and Keypoints in Precision-Critical AI appeared first on iMerit.
( 9
min )
Precision in AI is critical across domains like healthcare, autonomous driving, agriculture, and industrial inspection, where inaccuracies are unacceptable. Coarse
The post Why Semantic Segmentation Outperforms Bounding Boxes and Keypoints in Precision-Critical AI appeared first on iMerit.
( 9
min )
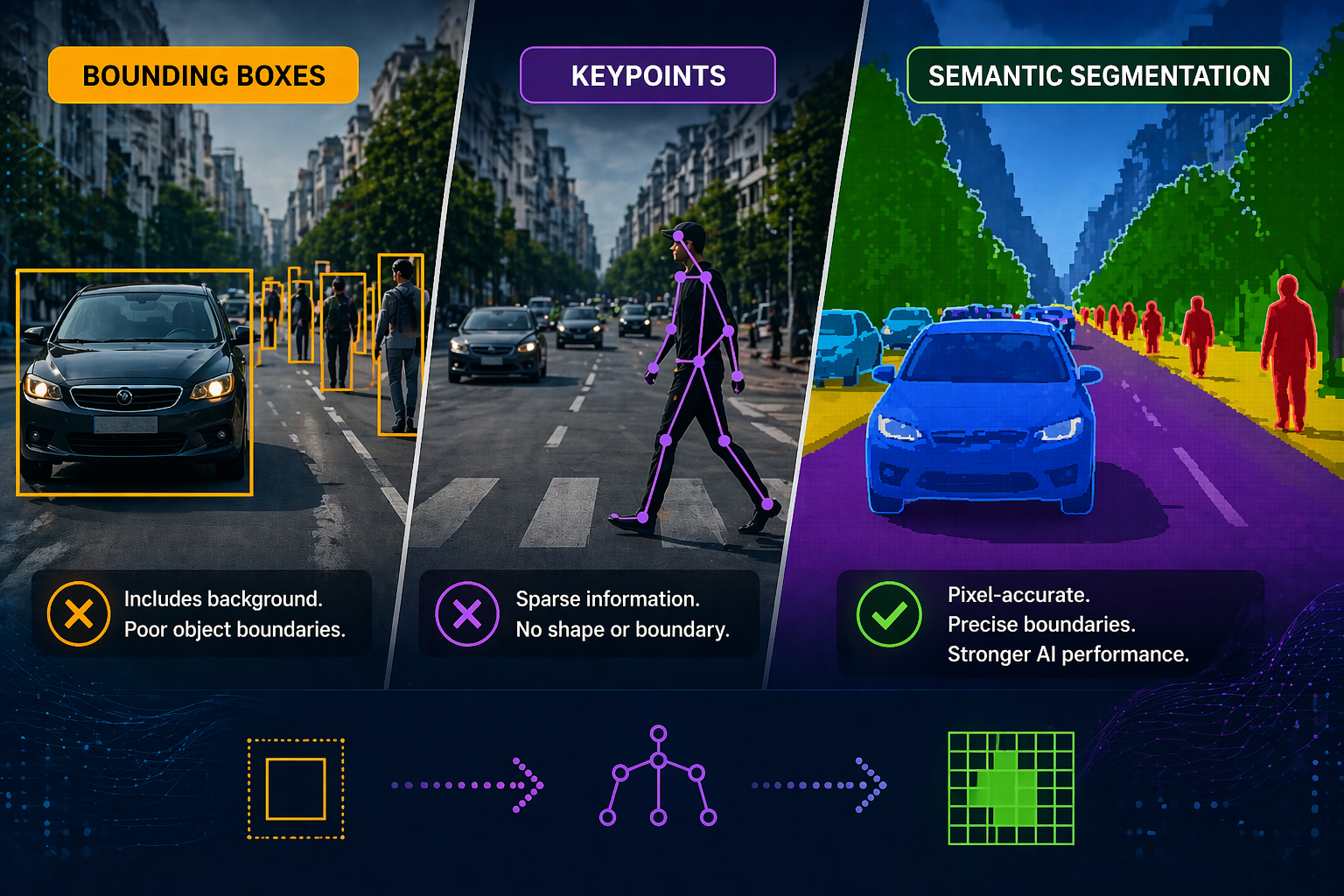 Precision in AI is critical across domains like healthcare, autonomous driving, agriculture, and industrial inspection, where inaccuracies are unacceptable. Coarse
The post Why Semantic Segmentation Outperforms Bounding Boxes and Keypoints in Precision-Critical AI appeared first on iMerit.
( 9
min )
Precision in AI is critical across domains like healthcare, autonomous driving, agriculture, and industrial inspection, where inaccuracies are unacceptable. Coarse
The post Why Semantic Segmentation Outperforms Bounding Boxes and Keypoints in Precision-Critical AI appeared first on iMerit.
( 9
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 6
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 6
min )
 Mario asked me why 18% of his shipments were late when every team hit their target. I built a live simulation, connected an AI agent, and let it investigate.
The post I Simulated an International Supply Chain and Let OpenClaw Monitor It appeared first on Towards Data Science.
( 16
min )
Mario asked me why 18% of his shipments were late when every team hit their target. I built a live simulation, connected an AI agent, and let it investigate.
The post I Simulated an International Supply Chain and Let OpenClaw Monitor It appeared first on Towards Data Science.
( 16
min )
 The silent gaps in synthetic data that only show up when your model is already in production.
The post Your Synthetic Data Passed Every Test and Still Broke Your Model appeared first on Towards Data Science.
( 17
min )
The silent gaps in synthetic data that only show up when your model is already in production.
The post Your Synthetic Data Passed Every Test and Still Broke Your Model appeared first on Towards Data Science.
( 17
min )
 It’s simpler than you think.
The post Lasso Regression: Why the Solution Lives on a Diamond appeared first on Towards Data Science.
( 28
min )
It’s simpler than you think.
The post Lasso Regression: Why the Solution Lives on a Diamond appeared first on Towards Data Science.
( 28
min )
 AI systems do not build themselves. Every chatbot, medical tool, and autonomous system depends on human judgment at each stage
The post Understanding Task Complexity in AI Training: From Simple Reviews to Expert-Level Annotation appeared first on iMerit.
( 11
min )
AI systems do not build themselves. Every chatbot, medical tool, and autonomous system depends on human judgment at each stage
The post Understanding Task Complexity in AI Training: From Simple Reviews to Expert-Level Annotation appeared first on iMerit.
( 11
min )
 AI systems do not build themselves. Every chatbot, medical tool, and autonomous system depends on human judgment at each stage
The post Understanding Task Complexity in AI Training: From Simple Reviews to Expert-Level Annotation appeared first on iMerit.
( 11
min )
AI systems do not build themselves. Every chatbot, medical tool, and autonomous system depends on human judgment at each stage
The post Understanding Task Complexity in AI Training: From Simple Reviews to Expert-Level Annotation appeared first on iMerit.
( 11
min )
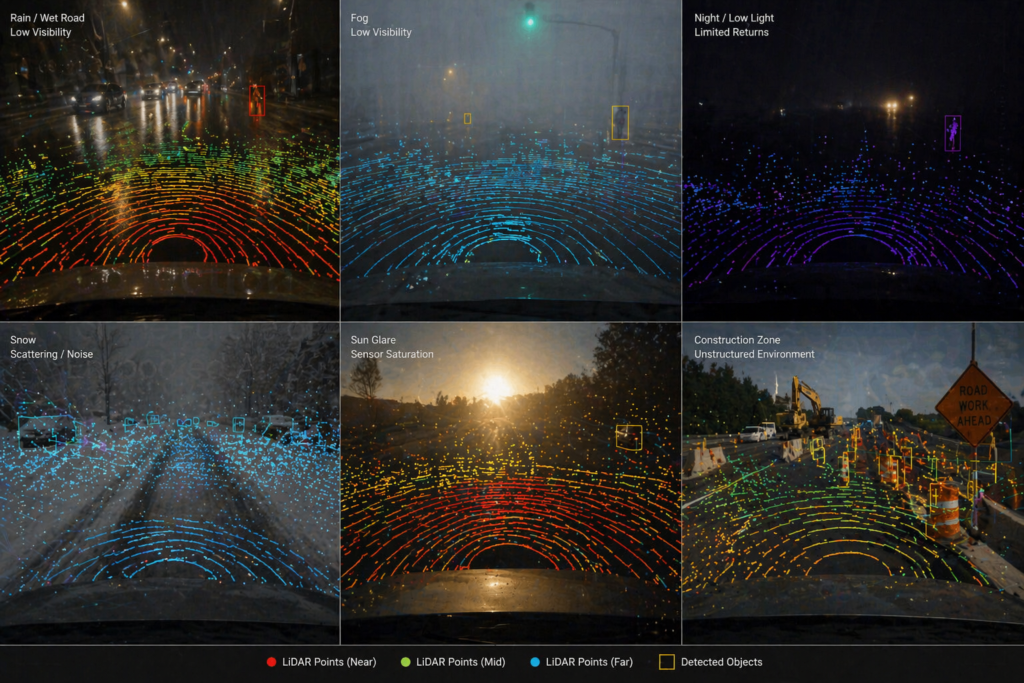 Autonomous systems rely on LiDAR for accurate perception and spatial awareness to perform reliably in many structured driving situations. However,
The post Strengthening Autonomous Systems with Edge-Case LiDAR Data appeared first on iMerit.
( 11
min )
Autonomous systems rely on LiDAR for accurate perception and spatial awareness to perform reliably in many structured driving situations. However,
The post Strengthening Autonomous Systems with Edge-Case LiDAR Data appeared first on iMerit.
( 11
min )
 Autonomous systems rely on LiDAR for accurate perception and spatial awareness to perform reliably in many structured driving situations. However,
The post Strengthening Autonomous Systems with Edge-Case LiDAR Data appeared first on iMerit.
( 11
min )
Autonomous systems rely on LiDAR for accurate perception and spatial awareness to perform reliably in many structured driving situations. However,
The post Strengthening Autonomous Systems with Edge-Case LiDAR Data appeared first on iMerit.
( 11
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 7
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 7
min )
 Your team shipped an LLM-based summaries feature to wave 1 workspaces at week 20 and now the post-launch doc is due. You need a causal effect number, a specific estimate you can defend to a statistici
( 16
min )
Your team shipped an LLM-based summaries feature to wave 1 workspaces at week 20 and now the post-launch doc is due. You need a causal effect number, a specific estimate you can defend to a statistici
( 16
min )
 Every time you spin up GPU infrastructure, you do the same thing: install CUDA drivers, DCGM, apply OS‑level GPU tuning, and fight dependency issues. Same old ritual every single time, wasting expensi
( 16
min )
Every time you spin up GPU infrastructure, you do the same thing: install CUDA drivers, DCGM, apply OS‑level GPU tuning, and fight dependency issues. Same old ritual every single time, wasting expensi
( 16
min )
 Turning free-to-use data into a hypothesis-ready dataset
The post Using Causal Inference to Estimate the Impact of Tube Strikes on Cycling Usage in London appeared first on Towards Data Science.
( 23
min )
Turning free-to-use data into a hypothesis-ready dataset
The post Using Causal Inference to Estimate the Impact of Tube Strikes on Cycling Usage in London appeared first on Towards Data Science.
( 23
min )
 Learn how Propensity Score Matching uncovers true causality in observational data. By finding "statistical twins," we eliminate selection bias to reveal the real impact of your interventions and business decisions.
The post Correlation vs. Causation: Measuring True Impact with Propensity Score Matching appeared first on Towards Data Science.
( 19
min )
Learn how Propensity Score Matching uncovers true causality in observational data. By finding "statistical twins," we eliminate selection bias to reveal the real impact of your interventions and business decisions.
The post Correlation vs. Causation: Measuring True Impact with Propensity Score Matching appeared first on Towards Data Science.
( 19
min )
 How I turned LLM persona interviews into a repeatable customer research workflow
The post From Ad Hoc Prompting to Repeatable AI Workflows with Claude Code Skills appeared first on Towards Data Science.
( 16
min )
How I turned LLM persona interviews into a repeatable customer research workflow
The post From Ad Hoc Prompting to Repeatable AI Workflows with Claude Code Skills appeared first on Towards Data Science.
( 16
min )
 Run OpenClaw assistant through alternative LLMs
The post How to Run OpenClaw with Open-Source Models appeared first on Towards Data Science.
( 15
min )
Run OpenClaw assistant through alternative LLMs
The post How to Run OpenClaw with Open-Source Models appeared first on Towards Data Science.
( 15
min )
 Deploying large language models (LLMs) in real-world, high-stakes settings is harder than it should be. In high-stakes settings like law, medicine, and cloud incident response, performance and reliability can quickly break down because adapting models to domain-specific requirements is a slow and manual process that is difficult to reproduce. The core challenge is domain adaptation, […]
The post AutoAdapt: Automated domain adaptation for large language models appeared first on Microsoft Research.
( 13
min )
Deploying large language models (LLMs) in real-world, high-stakes settings is harder than it should be. In high-stakes settings like law, medicine, and cloud incident response, performance and reliability can quickly break down because adapting models to domain-specific requirements is a slow and manual process that is difficult to reproduce. The core challenge is domain adaptation, […]
The post AutoAdapt: Automated domain adaptation for large language models appeared first on Microsoft Research.
( 13
min )
 A Blog post by NVIDIA on Hugging Face
( 6
min )
A Blog post by NVIDIA on Hugging Face
( 6
min )
 The next frontier of artificial intelligence is not a screen. It is a kitchen counter, a warehouse floor, and a
The post Scaling Egocentric Video Data Collection for the Future of Embodied AI appeared first on iMerit.
( 9
min )
The next frontier of artificial intelligence is not a screen. It is a kitchen counter, a warehouse floor, and a
The post Scaling Egocentric Video Data Collection for the Future of Embodied AI appeared first on iMerit.
( 9
min )
 The next frontier of artificial intelligence is not a screen. It is a kitchen counter, a warehouse floor, and a
The post Scaling Egocentric Video Data Collection for the Future of Embodied AI appeared first on iMerit.
( 9
min )
The next frontier of artificial intelligence is not a screen. It is a kitchen counter, a warehouse floor, and a
The post Scaling Egocentric Video Data Collection for the Future of Embodied AI appeared first on iMerit.
( 9
min )
 How you can build your own Thompson Sampling Algorithm object in Python and apply it to a hypothetical yet real-life example
The post DIY AI & ML: Solving The Multi-Armed Bandit Problem with Thompson Sampling appeared first on Towards Data Science.
( 22
min )
How you can build your own Thompson Sampling Algorithm object in Python and apply it to a hypothetical yet real-life example
The post DIY AI & ML: Solving The Multi-Armed Bandit Problem with Thompson Sampling appeared first on Towards Data Science.
( 22
min )
 For any data scientist who works in a team, being able to undo Git actions can be a life saver. This practical guide will teach you all you need to know to save the day.
The post Git UNDO : How to Rewrite Git History with Confidence appeared first on Towards Data Science.
( 26
min )
For any data scientist who works in a team, being able to undo Git actions can be a life saver. This practical guide will teach you all you need to know to save the day.
The post Git UNDO : How to Rewrite Git History with Confidence appeared first on Towards Data Science.
( 26
min )
 The hidden cost of probabilistic outputs in systems that demand reliability
The post I Replaced GPT-4 with a Local SLM and My CI/CD Pipeline Stopped Failing appeared first on Towards Data Science.
( 19
min )
The hidden cost of probabilistic outputs in systems that demand reliability
The post I Replaced GPT-4 with a Local SLM and My CI/CD Pipeline Stopped Failing appeared first on Towards Data Science.
( 19
min )
 As memory grows in RAG systems, accuracy quietly drops while confidence rises — creating a failure that most monitoring systems never detect. This article walks through a reproducible experiment showing why this happens and how a simple memory architecture fix restores reliability.
The post Your RAG Gets Confidently Wrong as Memory Grows – I Built the Memory Layer That Stops It appeared first on Towards Data Science.
( 21
min )
As memory grows in RAG systems, accuracy quietly drops while confidence rises — creating a failure that most monitoring systems never detect. This article walks through a reproducible experiment showing why this happens and how a simple memory architecture fix restores reliability.
The post Your RAG Gets Confidently Wrong as Memory Grows – I Built the Memory Layer That Stops It appeared first on Towards Data Science.
( 21
min )
 Learn how to use YOLO26-pose with Python for real-time keypoint estimation on images and videos, understand its RLE-based architecture, and explore its reported benchmarks on COCO-17.
YOLO26 Keypoint Estimation: Real-Time Pose Estimation with Ultralytics first appeared on LearnOpenCV.
( 26
min )
Learn how to use YOLO26-pose with Python for real-time keypoint estimation on images and videos, understand its RLE-based architecture, and explore its reported benchmarks on COCO-17.
YOLO26 Keypoint Estimation: Real-Time Pose Estimation with Ultralytics first appeared on LearnOpenCV.
( 26
min )
 A Blog post by Technology Innovation Institute on Hugging Face
( 6
min )
A Blog post by Technology Innovation Institute on Hugging Face
( 6
min )
 A Blog post by NVIDIA on Hugging Face
( 6
min )
A Blog post by NVIDIA on Hugging Face
( 6
min )
 We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 5
min )
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
( 5
min )
 The complex factors that determine the single evaluation number so many focus on. Plus, how this changes in the future.
The complex factors that determine the single evaluation number so many focus on. Plus, how this changes in the future.
 And what does it tell us?
The post What Does the p-value Even Mean? appeared first on Towards Data Science.
( 15
min )
And what does it tell us?
The post What Does the p-value Even Mean? appeared first on Towards Data Science.
( 15
min )
 Conceptual overview and practical guidance
The post Context Payload Optimization for ICL-Based Tabular Foundation Models appeared first on Towards Data Science.
( 21
min )
Conceptual overview and practical guidance
The post Context Payload Optimization for ICL-Based Tabular Foundation Models appeared first on Towards Data Science.
( 21
min )
 How to turn data into a strategic asset that enables faster decisions, reduces uncertainty, and helps the organization move toward its goals.
The post From Risk to Asset: Designing a Practical Data Strategy That Actually Works appeared first on Towards Data Science.
( 18
min )
How to turn data into a strategic asset that enables faster decisions, reduces uncertainty, and helps the organization move toward its goals.
The post From Risk to Asset: Designing a Practical Data Strategy That Actually Works appeared first on Towards Data Science.
( 18
min )
 Doug Burger, sustainability expert Amy Luers, and optimization researcher Ishai Menache examine the global emissions implications of datacenter operations, efficiency gains, and AI's potential across electrification, materials, and food systems.
The post Can we AI our way to a more sustainable world? appeared first on Microsoft Research.
( 47
min )
Doug Burger, sustainability expert Amy Luers, and optimization researcher Ishai Menache examine the global emissions implications of datacenter operations, efficiency gains, and AI's potential across electrification, materials, and food systems.
The post Can we AI our way to a more sustainable world? appeared first on Microsoft Research.
( 47
min )
 Open source. 5-minute setup. Vector RAG done right—try it yourself.
The post Proxy-Pointer RAG: Structure Meets Scale at 100% Accuracy with Smarter Retrieval appeared first on Towards Data Science.
( 19
min )
Open source. 5-minute setup. Vector RAG done right—try it yourself.
The post Proxy-Pointer RAG: Structure Meets Scale at 100% Accuracy with Smarter Retrieval appeared first on Towards Data Science.
( 19
min )